
[Python] 웹 크롤링 #1
Updated:
방학을 맞이하여 python을 공부하다가 프로젝트로 뭐가 있을까 하다가 친구의 추천으로 크롤링을 진행하게 되었다. 크롤링에 대해 공부를 어느 정도 하긴 했지만 내가 직접 구현하기 위해 다시 공부를 하고 진행을 하게 되었다. 우선 목표는 리그 오브 레전드 게임의 전적을 보여주는 사이트 op.gg 를 크롤링하는 것이었다. 나중에는 더 어려운 크롤링도 할 수 있겠지만 우선은 처음이니깐 쉬워보이는 것부터 할 것이다.
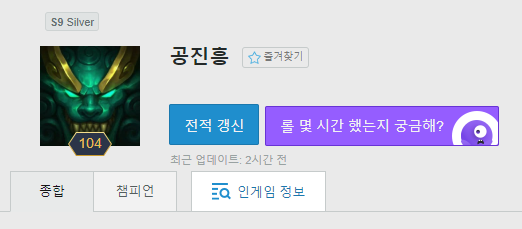

내가 크롤링을 진행할 부분은 위의 두 부분이다. 프로그램을 실행하면 input으로 전적을 검색하고 싶은 소환사의 이름을 입력할 수 있다. 입력을 받게 되면 op.gg 에서 검색을 하고 그 결과를 크롤링하여 결과로 출력한다. 참고로 위 아이디는 내 아이디지만 게임을 잘 안해서 실버지 실력은 골드 정도이다.
구현은 두 가지 함수로 진행했다.
- input을 받고 크롤링 함수를 호출하기 위한 main 함수
- 크롤링을 진행하는 Crawling 함수
def main():
search_user=input("소환사를 검색하세요:")
Crawling(search_user)
main()
위의 코드가 main 함수이다. 생각보다 별 거 없다. 우선 간단한 main을 구현하고 복잡한 Crawling 함수를 구현하는 순서로 진행했다. 어떤 변수들이 필요할 지 확인하기 위해 op.gg에서 F12를 통해 확인을 진행했다.
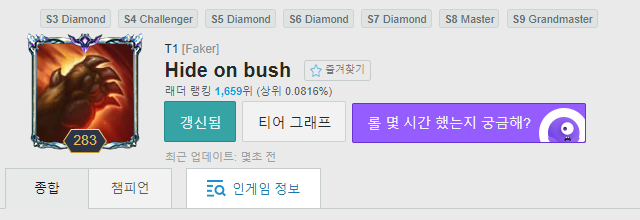
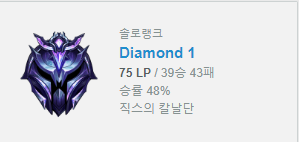
페이커다. 나랑 플레이 스타일이 가장 비슷한 선수이기 때문에 골랐다. 간단한 크롤링을 구현할 것이므로 필요한 변수는 많지 않았다.
- 소환사 이름
- 랭킹
- 소환사 레벨
- 랭크의 타입(솔로랭크, 자유 5:5 랭크)
- 현재 티어
- 점수
- 승,패, 승률
- Unranked (언랭인지 아닌지 판별)
대충 이 정도가 필요하므로 아래와 크롬의 개발자 도구를 켜서 필요한 태그들의 이름을 찾아내었다. (F12 단축키를 사용하면 편하다.)
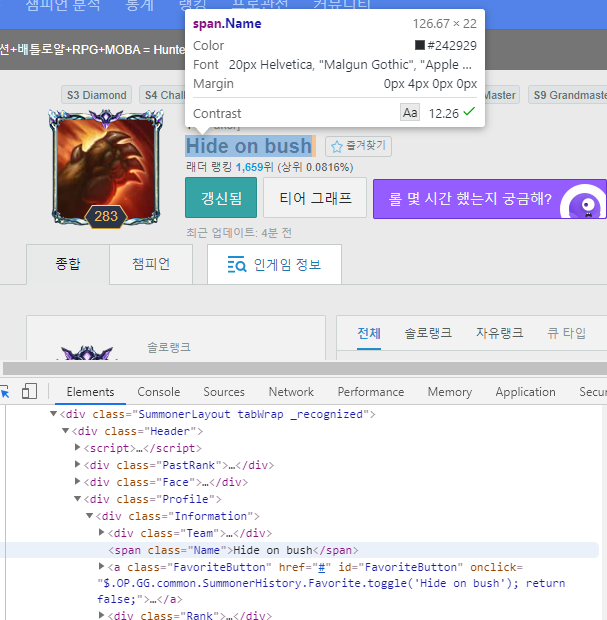
그 다음으로 크롤링을 진행하기 위한 html 가져오기 및 파싱을 진행하여 나에게 필요한 데이터를 추출했다. 이 작업에서는 beautifulsoup 라이브러리를 사용했다. beautifulsoup 라이브러리의 설치법은 아래와 같다.
pip install beautifulsoap4
이제 사용해보자.
header={'Accept-Language':'ko_KR,en;q=0.8'}
url="https://www.op.gg/summoner/userName="+search_user
response=requests.get(url,headers=header)
html=response.text
soup=BeautifulSoup(html, 'html.parser')
위의 코드에서 header 부분을 따로 설정한 이유는 op.gg에서 크롤링을 위해 파싱해오는 데이터가 영어로 파싱되기 때문에 ko_KR,en’q=0.8로 설정해주었다. 그리고 나서 main에서 입력한 찾고자 하는 소환사의 이름을 받아와서 search_user를 통해 url을 얻어온다.
그리고 response 변수에 url과 header 값으로 서버에게 GET 요청을 하고 받는 html 소스를 저장한다.
html 변수에는 response 변수에 담긴 html 소스를 가져온다.
마지막으로 파싱할 문서인 html과 파싱 방식인 html.parser를 인자로 넣어 beautifulsoup 객체를 생성한다.
이제 어느 정도 준비는 끝났고 하나씩 크롤링을 진행해보자. 먼저 소환사 이름 크롤링을 진행할 것이다.
for i in soup.select('div.Information > span.Name'):
user_name.append(i.text)
소환사 이름 크롤링 코드이다. 사실 이 부분에서 살짝 애를 먹었던게 내가 원한건 ‘hide on bush’였는데 겹치는 span.Name인 ‘Faker’가 있었기 때문에 ‘Faker’가 출력되었다. 하지만 상위 클래스를 직접 지정해주고 ‘>’ 표시로 자식임을 표시해주어 해결할 수 있었다. ‘>’를 사용할 때 주의할 점이 있는데 기호의 앞 뒤로 공백문자가 필요하다는 점이다. 실수하지 않기 위해 알아두자.
소환사 이름을 크롤링한 것과 같이 나머지 변수들에 대해서도 크롤링을 진행해준다.
#소환사 이름 크롤링
for i in soup.select('div.Information > span.Name'):
user_name.append(i.text)
if not user_name:
isUser=False
else:
#소환사 레벨 크롤링
for i in soup.select('span.Level.tip'):
user_level.append(i.text)
#소환사 랭킹 크롤링
for i in soup.select('div.LadderRank'):
ranking.append(i.text)
if len(ranking)==0:
s_unrank=True
f_unrank=True
#솔로 랭크 타입 크롤링
for i in soup.select('div.RankType'):
rank_type.append(i.text)
#솔랭 티어 크롤링
for i in soup.select('div.TierRank'):
tier.append(i.text)
#자유 랭크 타입 크롤링
for i in soup.select('div.sub-tier__rank-type'):
sub_rank_type.append(i.text)
#자유 랭크 티어 크롤링
for i in soup.select('div.sub-tier__rank-tier'):
sub_tier.append(i.text)
if isUser==True:
sub_tier[0]=sub_tier[0].strip('\n\t')
if 'Unranked' in str(sub_tier[0]):
f_unrank=True
#점수 크롤링
for i in soup.select('span.LeaguePoints'):
point.append(i.text)
#자유랭크 점수 크롤링
for i in soup.select('div.sub-tier__league-point'):
sub_point.append(i.text)
#승리 크롤링
for i in soup.select('span.wins'):
win.append(i.text)
#패배 크롤링
for i in soup.select('span.losses'):
lose.append(i.text)
#승률 크롤링
for i in soup.select('span.winratio'):
ratio.append(i.text)
#자유랭크 승률 크롤링
for i in soup.select('div.sub-tier__gray-text'):
sub_ratio.append(i.text)
if len(sub_ratio)!=0:
sub_ratio[0]=sub_ratio[0].rstrip()
크롤링 부분에 대한 코드이다. 처음부터 이렇게 코드가 작성되지는 않았다. 하지만 확인을 하면서 코드를 짜다보니 두 가지 문제가 있었다.
-
소환사 이름이 없는 경우
따로 isUser 플래그를 하나 세워 이름이 없다면 False로 설정해서 해결할 수 있었다.
-
Unranked인 경우
이 부분에서 살짝 시간을 소요했다. Unranked인 경우와 랭크 게임을 진행한 사람들의 페이지 소스를 보며 비교한 결과 Unranked인 사람들은 페이지에 랭킹이 출력되지 않았다. 이 부분을 이용하여 소환사 랭킹을 크롤링한 직후 ranking 변수에 값이 없다면 unrank 플래그를 True로 설정했다. 여기서 또 문제가 자유 랭크만 Unranked인 경우가 있다는 것이다. 이 경우는 자유 랭크의 티어를 크롤링한 직후에서 조건을 걸어 해결한다. 자유 랭크의 티어를 크롤링한 결과는 sub_tier 변수에 들어가게 되는데 이 변수에 Unranked가 들어 있다면 unrank 플래그를 False로 설정했다.
이제 크롤링은 완료했고 출력만이 남았다.
if not isUser:
print("존재하지 않는 소환사입니다.")
else:
print('소환사 이름:' + user_name[0])
print('소환사 레벨:' + user_level[0])
if s_unrank:
print(user_name[0] + '님의 솔로 랭크는 Unranked 입니다...')
else:
print('소환사 랭킹:' + ranking[0].strip('\n\t'))
print(rank_type[0] + ' : ' + tier[0])
print('\t\t\t'+'(' +ratio[0]+')')
print('\t\t\t'+' - '+point[0].strip('\n\t')+'/ ' + win[0], lose[0])
if f_unrank:
print(user_name[0] + '님의 자유 랭크는 Unranked 입니다...')
else:
print(sub_rank_type[0] + ' : ' + sub_tier[0].lstrip()+' ('+sub_ratio[0].lstrip()+')')
print('\t\t\t\t'+' - ' + sub_point[0])
우선 존재하지 않는 소환사의 이름을 검색했다면 그에 맞는 에러를 출력한다. 그 경우가 아니라면 크롤링한 결과를 하나씩 출력한다. op.gg 홈페이지의 순서에 맞춰 하나씩 출력했다.
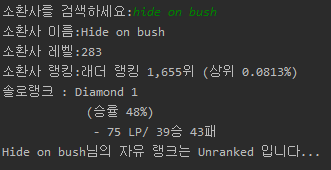
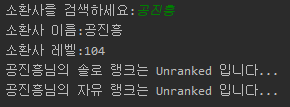
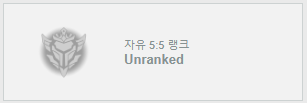
정상적으로 출력되는 모습을 볼 수 있다. 자유 랭크만 하는 사람의 경우도 찾아보려 했지만 찾지 못했다…
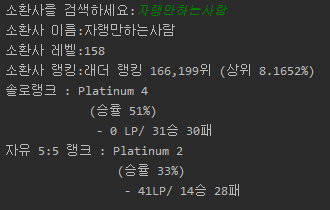
‘자랭만하는사람’인데 솔랭도 했다.
고찰
크롤링. 처음에는 어려웠다 솔직히. 근데 하나하나 하다보니 좀 재미도 느껴졌다. 특히 내가 좋아하는 주제에 대해서 진행하다보니 더 흥미가 느껴졌다. 어려움도 있었다. 출력 부분에서 내가 원하는 대로 출력이 안되서 짜증이 날 정도였다. 결국 strip으로 공백을 제거하고 난리를 피워서 예쁘게 만들엇다. 코드는 더 간결하게 만들 수 있을 거 같은데 시간이 좀 많이 걸릴 거 같다. 우선은 크롤링 경험을 해봤다는 것에 만족한다. 다음에는 더 어려운 크롤링을 도전해봐야겠다.
Leave a comment