
[JAVA] 이것이 자바다_6
Updated:
객체 지향 프로그래밍의 두번째 정리.
클래스의 구성 멤버에 대해 차근차근 정리해보자.
클래스의 구성 멤버
클래스에는 객체가 가져야 할 구성 멤버가 선언된다.
구성 멤버에는 필드(Field), 생성자(Constructor), 메소드(Method)가 있다.
이 구성 멤버들은 생략되거나 복수 개가 작성될 수 있다.
public class ClassName {
// 필드 : 객체의 데이터가 저장되는 곳
int filedName;
// 생성자 : 객체 생성 시 초기화 역할 담당
ClassName() {...}
// 메소드 : 객체의 동작에 해당하는 실행 블록
void methodName() {...}
}
각 구성 멤버에 대해 간단히 알아보자.
필드
필드는 객체의 고유 데이터, 부품 객체, 상태 정보를 저장하는 곳이다.
선언 형태는 변수와 비슷하지만, 필드를 변수라고 부르지 않는다.
변수는 생성자와 메소드 내에서만 사용되고 생성자와 메소드가 실행 종료되면 자동 소멸된다.
하지만 필드는 생성자와 메소드 전체에서 사용되며 객체가 소멸되지 않는 한 객체와 함께 존재한다.
생성자
생성자는 new 연산자로 호출되는 특별한 중괄호 {} 블록이다.
생성자의 역할은 객체 생성 시 초기화를 담당한다.
필드를 초기화하거나, 메소드를 호출해서 객체를 사용할 준비를 한다.
생성자는 메소드와 비슷하게 생겼지만, 클래스 이름으로 되어 있고 리턴 타입이 없다.
메소드
메소드는 객체의 동작에 해당하는 중괄호 {} 블록이다.
중괄호 블록은 이름을 가지고 있는데, 이것이 메소드 이름이다.
메소드를 호출하게 되면 중괄호 블록에 있는 모든 코드들이 일괄절으로 실행된다.
메소드는 필드를 읽고 수정하는 역할도 하지만, 다른 객체를 생성해서 다양한 기능을 수행하기도 한다.
메소드는 객체 간의 데이터 전달의 수단으로 사용된다.
외부로부터 매개값을 받을 수 있고, 실행 후 어떤 값을 리턴할 수도 있다.
이제 각 구성 멤버에 대해 자세히 알아보자.
필드
필드는 객체의 고유 데이터, 객체가 가져야 할 부품, 객체의 현재 상태 데이터를 저장하는 곳이다.
자동차 객체를 예로 들어 보면 제작회사, 모델, 색깔, 최고 속도는 고유 데이터에 해당하고,
현재 속도, 엔진 회전 수는 상태 데이터에 해당한다.
그리고 차체, 엔진, 타이어는 부품에 해당한다.
따라서 자동차 클래스를 설계할 때 이 정보들은 필드로 선언되어야 한다.
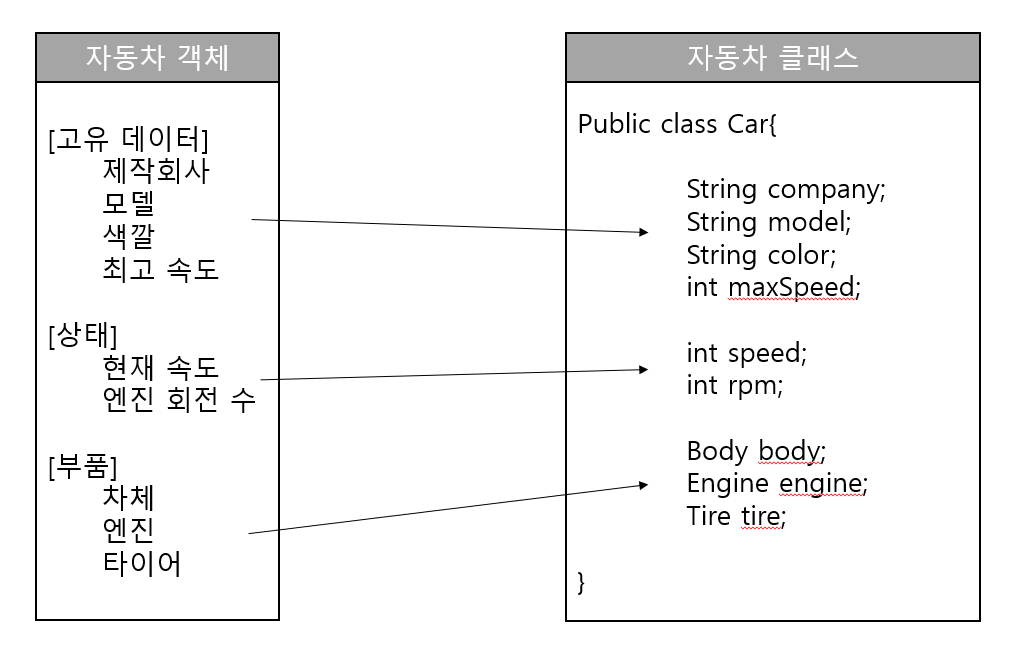
필드 선언
필드 선언은 클래스 중괄호 {} 블록 어디서나 존재할 수 있다.
생성자 선언과 메소드 선언의 앞과 뒤 어떤 곳에서도 필드 선언이 가능하다.
하지만 생성자와 메소드 중괄호 블록 내부에는 선언될 수 없다.
생성자와 메소드 중괄호 블록 내부에 선언된 것은 모두 로컬 변수가 된다.
필드 선언은 변수의 선언 형태와 비슷하다.
그래서 일부 사람들은 클래스 멤버 변수라고 부르기도 하는데, 필드라는 용어를 사용하는 것이 좋다.
다음은 올바르게 필드를 선언한 예를 보여준다.
String company = "현대자동차";
String model = "그랜져";
int maxSpeed = 300;
int productionYear;
int currentSpeed;
boolean engineStart;
초기값이 지정되지 않은 필드들은 객체 생성 시 자동으로 기본 초기값으로 설정된다.
필드 사용
필드를 사용한다는 것은 필드값을 읽고, 변경하는 작업을 말한다.
클래스 내부의 생성자나 메소드에서 사용할 경우 단순히 필드 이름으로 읽고 변경하면 되지만,
클래스 외부에서 사용할 경우 우선적으로 클래스로부터 객체를 생성한 뒤 필드를 사용해야 한다.
그 이유는 필드는 객체에 소속된 데이터이므로 객체가 존재하지 않으면 필드도 존재하지 않기 때문이다.
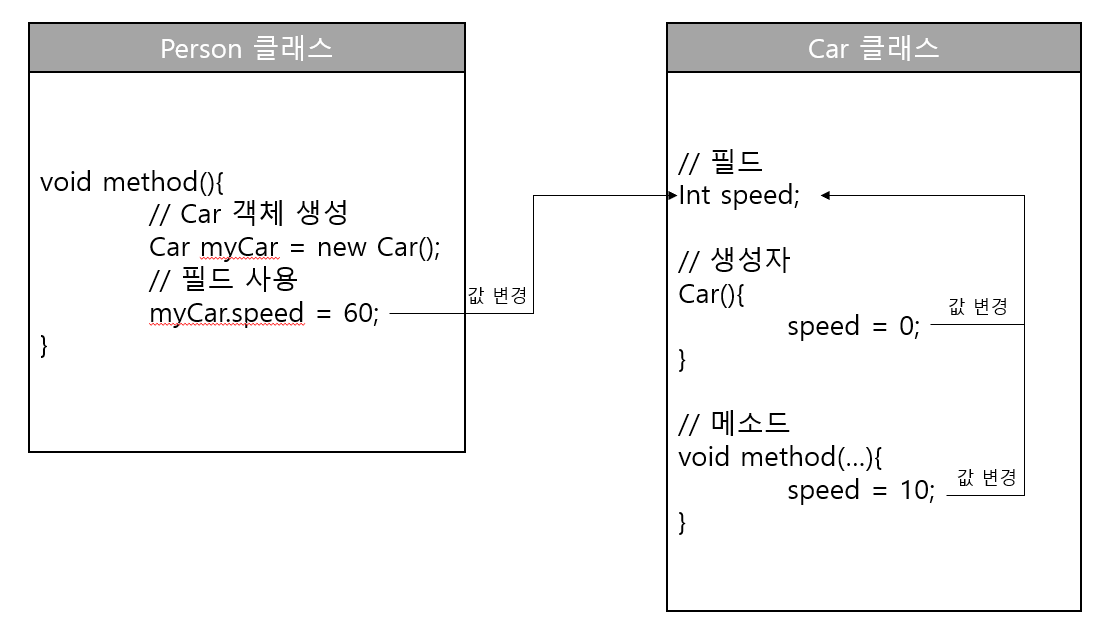
위 그림을 보면 Car 클래스의 speed 필드는 생성자와 메소드에서 변경이 가능하다.
사용 방법은 변수와 동일한데, 차이점은 변수는 자신이 선언된 생성자 또는 메소드 블록 내부에서만 사용할 수 있는 반면 필드는
생성자와 모든 메소드에서 사용이 가능하다.
외부 Person 클래스에서 Car 클래스의 speed 필드 값을 사용하려면 Car 객체를 우선 생성해야 한다.
Car myCar = new Car();
myCar 변수가 Car 객체를 참조하게 되면 도트(.) 연산자를 사용해서 speed 필드에 접근할 수 있다.
생성자
생성자는 new 연산자와 같이 사용되어 클래스로부터 객체를 생성할 때 호출되어 객체의 초기화를 담당한다.
객체 초기화란 필드를 초기화하거나, 메소드를 호출해서 객체를 사용할 준비를 하는 것을 말한다.
생성자를 실행시키지 않고는 클래스로부터 객체를 만들 수 없다.
new 연산자에 의해 생성자가 성공적으로 실행되면 힙(heap) 영역에 객체가 생성되고 객체의 주소가 리턴된다.
리턴된 객체의 주소는 클래스 타입 변수에 저장되어 객체에 접근할 때 이용된다.
만약 생성자가 성공적으로 실행되지 않고 예외(에러)가 발생했다면 객체는 생성되지 않는다.
기본 생성자
모든 클래스는 생성자가 반드시 존재하며, 하나 이상을 가질 수 있다.
우리가 클래스 내부에 생성자 선언을 생략했다면 컴파일러는 다음과 같이 중괄호 {} 블록 내용이 비어있는 기본 생성자(Default Constructor)를 바이트 코드에 자동 추가시킨다.
[public] 클래스() { }
클래스가 public class로 선언되면 기본 생성자에도 public이 붙지만, 클래스가 public 없이 class로만 선언되면 기본 생성자에도 public이 붙지 않는다.
예를 들어 Car 클래스를 설계할 때 생성자를 생략하면 다음과 같이 기본 생성자가 생성된다.
public class Car{
// 소스 파일(Car.java)
}
public class Car{
// 바이트 코드 파일(Car.class)
public Car() { } // 자동 추가
}
그렇기 때문에 클래스에 생성자를 선언하지 않아도 다음과 같이 new 연산자 뒤에 기본 생성자를 호출해서 객체를 생성시킬 수 있다.
Car myCar = new Car();
그러나 클래스에 명시적으로 선언한 생성자가 한 개라도 있으면, 컴파일러는 기본 생성자를 추가하지 않는다.
명시적으로 생성자를 선언하는 이유는 객체를 다양하게 초기화하기 위해서이다.
생성자 선언
기본 생성자 대신 우리가 생성자를 명시적으로 선언하려면 다음과 같은 형태로 작성한다.
// 생성자 블록
클래스(매개변수선언, ...) {
// 객체의 초기화 코드
}
생성자는 메소드와 비슷한 모양이나, 리턴 타입이 없고 클래스 이름과 동일하다.
생성자 블록 내부에는 객체 초기화 코드가 작성되는데, 일반적으로 필드에 초기값을 저장하거나 메소드를 호출하여 객체 사용 전에 필요한 준비를 한다.
매개 변수 선언은 생략할 수도 있고, 여러 개를 선언해도 좋다.
매개 변수는 new 연산자로 생성자를 호출할 때 외부의 값을 생성자 블록 내부로 전달하는 역할을 한다.
예를 들어 다음과 같이 Car 생성자를 호출할 때 세 개의 값을 제공한다고 보자.
Car myCar = new Car("그랜져", "검정", 300);
두 개의 매개값은 String 타입이고 마지막 매개값은 int 타입인 것을 볼 수 있다.
세 매개값을 생성자가 받기 위해서는 다음과 같이 생성자를 선언해야 한다.
public class Car{
// 생성자
Car(String model, String color, int maxSpeed){ ... }
}
클래스에 생성자가 명시적으로 선언되어 있을 경우에는 반드시 선언된 생성자를 호출해서 객체를 생성해야만 한다.
다음의 예시를 통해 이해를 돕자.
public class Car{
// 생성자
Car(String color, int cc){
}
}
public calss CarExample{
public static void main(String[] args){
Car myCar = new Car("검정", 3000); // 올바른 예시
// Car myCar = new Car(); // (x) 기본 생성자를 호출할 수 없다.
}
}
필드 초기화
클래스로부터 객체가 생성될 때 필드는 기본 초기값으로 자동 설정된다.
만약 다른 값으로 초기화를 하고 싶다면 두 가지 방법이 있다.
하나는 필드를 선언할 때 초기값을 주는 방법이고, 또 다른 하나는 생성자에서 초기값을 주는 방법이다.
필드를 선언할 때 초기값을 주게 되면 동일한 클래스로부터 생성되는 객체들은 모두 같은 데이터를 갖는다.
물론 객체 생성 후 변경이 가능하지만, 객체 생성 시점에는 필드의 값이 모두 같다.
하지만 객체 생성 시점에 외부에서 제공되는 다양한 값들로 초기화되어야 한다면 생성자에서 초기화를 해야 한다.
아래의 코드를 통해 이해를 돕자.
public class Korean {
// 필드
String nation = "대한민국";
String name;
String ssn;
// 생성자
public Korean(String n, String s){
name = n;
ssn = s;
}
}
아래 코드에서 “박자바”, “김자바”는 매개 변수 n을 통해 전달되고, “011225-1234567”, “930525-0654321”은 매개 변수 s를 통해 전달된다.
이 값들은 각각 name 필드와 ssn 필드의 초기값으로 사용된다.
Korean k1 = new Korean("박자바", "011225-1234567");
Korean k2 = new Korean("김자바", "930525-0654321");
매개 변수의 이름은 너무 짧으면 코드의 가독성이 좋지 않기 때문에 가능하면 초기화시킬 필드 이름과 비슷하거나 동일한 이름을 사용한다.
관례적으로는 필드와 동일한 이름을 갖는 매개 변수를 사용하는데, 이 경우 필드와 매개 변수 이름이 동일하기 때문에 생성자 내부에서 해당 필드에 접근할 수 없다.
왜냐하면 동일한 이름의 매개 변수가 사용 우선순위가 높기 때문이다.
해결 방법은 필드 앞에 “this.”를 붙이면 된다.
this는 객체 자신의 참조인데, 우리가 우리 자신을 “나”라고 하듯이 객체가 객체 자신을 this라고 한다.
this를 이용하여 Korean 생성자를 수정하면 다음과 같다.
public Korean(String name, String ssn){
this.name = name;
this.ssn = ssn;
}
생성자 오버로딩
외부에서 제공되는 다양한 데이터들을 이용해서 객체를 초기화하려면 생성자도 다양화될 필요가 있다.
Car 객체를 생성할 때 외부에서 제공되는 데이터가 없다면 기본 생성자로 Car 객체를 생성해야 하고, 외부에서 model 데이터가 제공되거나 model과 color가 제공될 경우에도 Car 객체를 생성할 수 있어야 한다.
생성자가 하나뿐이라면 이러한 요구 조건을 수용할 수 없다.
그래서 자바는 다양한 방법으로 객체를 생성할 수 있도록 생성자 오버로딩(Overloading) 을 제공한다.
생성자 오버리딩 이란 매개 변수를 달리하는 생성자를 여러 개 선언하는 것을 말한다.
다음은 Car 클래스에서 생성자를 오버로딩한 예를 보여준다.
public class Car{
Car() {...}
Car(String model) {...}
Car(String model, String color) {...}
Car(String model, String color, int maxSpeed) {...}
}
생성자 오버로딩 시 주의할 점은 매개 변수의 타입과 개수 그리고 선언된 순서가 똑같을 경우 매개 변수 이름만 바꾸는 것은 오버로딩이라고 볼 수 없다.
다음과 같은 경우가 해당된다.
Car(String model, String color) {...}
Car(String color, String model) {...} // 오버로딩이 아님
생성자가 오버로딩되어 있을 경우, new 연산자로 생성자를 호출할 때 제공되는 매개값의 타입과 수에 의해 호출될 생성자가 결정된다.
다음은 다양한 방법으로 Car 객체를 생성하는 예이다.
Car car1 = new Car();
Car car2 = new Car("그랜져");
Car car3 = new Car("그랜져", "흰색");
Car car4 = new Car("그랜져", "흰색", 300);
다른 생성자 호출(this())
생성자 오버로딩이 많아질 경우 생성자 간의 중복된 코드가 발생할 수 있다.
매개 변수의 수만 다르게 하고 필드 초기화 내용이 비슷한 생성자에서 이러한 현상을 많이 볼 수 있다.
이 경우에는 필드 초기화 내용은 한 생성자에만 집중적으로 작성하고 나머지 생성자는 초기화 내용을 가지고 잇는 생성자를 호출하는 방법으로 개선할 수 있다.
생성자에서 다른 생성자를 호출할 때에는 다음과 같이 this() 코드를 사용한다.
클래스( [매개변수선언, ...]){
this(매개변수, ... , 값, ...);
실행문;
}
this()는 자신의 다른 생성자를 호출하는 코드로 반드시 생성자의 첫줄에서만 허용 된다.
this()의 매개값은 호출되는 생성자의 매개 변수 타입에 맞게 제공해야 한다.
this() 다음에는 추가적인 실행문들이 올 수 있다.
이 말은 호출되는 생성자의 실행이 끝나면 원래 생성자로 돌아와서 다음 실행문을 진행한다는 뜻이다.
다음 코드를 보며 생성자 오버로딩에서 생기는 중복 코드를 제거해본다.
Car(String model){
this.model = model;
this.color = "은색";
this.maxSpeed = 250;
}
Car(String model, String color){
this.model = model;
this.color = color;
this.maxSpeed = 250;
}
Car(String model, String color, int maxSpeed){
this.model = model;
this.color = color;
this.maxSpeed = maxSpeed;
}
위의 코드에서 세 개의 생성자 내용이 비슷하므로 앞의 두 개의 생성자에서 this()를 사용해서 마지막 생성자인 Car(String model, String color, int maxSpeed)를 호출하도록 수정하면 중복 코드를 최소화시킬 수 있다.
아래의 코드는 중복 코드를 최소화시킨 코드이다.
Car(String model){
this(model, "은색", 250);
}
Car(String model, String color){
this(model, color, 250);
}
Car(String model, String color, int maxSpeed){
this.model = model;
this.color = color;
this.maxSpeed = maxSpeed;
}
메소드
메소드는 객체의 동작에 해당하는 중괄호 {} 블록을 말한다.
중괄호 블록은 이름을 가지고 있는데, 이것이 메소드 이름이다.
메소드를 호출하게 되면 중괄호 블록에 있는 모든 코드들이 일괄적으로 실행된다.
메소드는 필드를 읽고 수정하는 역할도 하지만, 다른 개겣를 생성해서 다양한 기능을 수행하기도 한다.
메소드는 객체간의 데이터 전달의 수단으로 사용된다.
외부로부터 매개값을 받을 수도 있고, 실행 후 어떤 값을 리턴할 수도 있다.
메소드 선언
메소드 선언은 선언부(리턴타입, 메소드이름, 매개변수선언)와 실행 블록으로 구성된다.
리턴 타입
리턴 타입은 메소드가 실행 후 리턴하는 값의 타입을 말한다.
메소드는 리턴값이 있을 수도 있고 없을 수도 있다.
메소드가 실행 후 결과를 호출한 곳에 넘겨줄 경우에는 리턴값이 있어야 한다.
예시로 전자계산기 객체에서 전원을 켜는 powerOn() 메소드와 두 수를 나누는 기능인 divide 메소드가 있다고 가정해보자.
divide() 메소드는 나눗셈의 결과를 리턴해야 하지만 powerOn() 메소드는 전원만 켜면 그만이다.
따라서 powerOn() 메소드는 리턴값이 없고, divide() 메소드는 리턴값이 있다.
아래와 같이 리턴값이 없는 메소드는 리턴 타입에 void가 와야 하며 리턴값이 있는 메소드는 리턴값의 타입이 와야 한다.
void powerOn() {...}
double divide(int x, int y) {...}
호출 방식도 달라지게 된다.
powerOn();
double result = divied(10, 20);
powerOn() 메소드는 리턴값이 없기 때문에 변수에 저장할 내용이 없다.
단순히 메소드만 호출하면 된다.
그러나 divide() 메소드는 10을 20으로 나눈 후 0.5를 리턴하므로 이것을 저장할 변수가 있어야 한다.
리턴값을 받기 위해 변수는 메소드의 리턴 타입인 double 타입으로 선언되어야 한다.
그러나 리턴 타입이 있다고 해서 반드시 리턴값을 변수에 저장할 필요는 없다.
리턴값이 중요하지 않고, 메소드 실행이 중요할 경우에는 다음과 같이 변수 선언 없이 메소드만 호출할 수도 있다.
divide(10,20);
메소드 이름
메소드 이름은 자바 식별자 규칙에 맞게 작성하면 되는데, 다음 사항에 주의하면 된다.
- 숫자로 시작하면 안 되고, $와 _를 제외한 특수 문자를 사용하지 말아야 한다.
- 관례적으로 메소드명은 소문자로 작성한다.
- 서로 다른 단어가 혼합된 이름이라면 뒤이어 오는 단어의 첫머리 글자는 대문자로 작성한다.
다음은 잘 작성된 메소드 이름이다.
void run() {...}
void startEngine() {...}
String getName() {...}
int[] getScores() {...}
매개 변수 선언
매개 변수는 메소드가 실행할 때 필요한 데이터를 외부로부터 받기 위해 사용된다.
매개 변수도 필요한 경우가 있고 필요 없는 경우가 있다.
예시로 powerOn() 메소드는 그냥 전원만 켜면 그만이지만, divide() 메소드는 나눗셈할 두 수가 필요하다.
따라서 powerOn() 메소드는 매개 변수가 필요 없고, divide() 메소드는 매개 변수가 2개 필요하다.
매개 변수의 수를 모를 경우
메소드의 매개 변수는 개수가 이미 정해져 있는 것이 일반적이지만, 경우에 따라서는 메소드를 선언할 때 매개 변수의 개수를 알 수 없는 경우가 있다.
예를 들어 여러 개의 수를 모두 합산하는 메소드를 선언해야 한다면, 몇 개의 매개 변수가 입력될지 알 수 없기 때문에 매개 변수의 개수를 결정할 수도 없다.
해결책은 다음과 같이 매개 변수를 배열 타입으로 선언하는 것이다.
int sum1(int[] values) { }
sum1() 메소드를 호출할 때 배열을 넘겨줌으로써 배열의 항목 값들을 모두 전달할 수 있다.
배열의 항목 수는 호출할 때 결정된다.
int[] values = {1, 2, 3};
int result = sum1(values);
int result = sum1(new int[] {1, 2, 3, 4, 5});
매개 변수를 배열 타입으로 선언하면, 메소드를 호출하기 전에 배열을 생성해야 하는 불편한 점이 있다.
그래서 배열을 생성하지 않고 값의 리스트만 넘겨주는 방법도 있다.
다음과 같이 sum2() 메소드의 매개 변수를 “···”를 사용해서 선언하게 되면, 메소드 호출 시 넘겨준 값의 수에 따라 자동으로 배열이 생성되고 매개값으로 사용된다.
int sum2(int ··· values) { }
“···”로 선언된 매개 변수의 값은 다음과 같이 메소드 호출 시 리스트로 나열해주면 된다.
int result = sum2(1, 2, 3);
int result = sum2(1, 2, 3, 4, 5);
“···”로 선언된 매개 변수는 배열 타입이므로 다음과 같이 배열을 직접 매개값으로 사용해도 좋다.
int[] values = {1, 2, 3};
int result = sum2(values);
int result = sum2(new int[] {1, 2, 3, 4, 5});
리턴(return)문
리턴값이 있는 메소드
메소드 선언에 리턴 타입이 있는 메소드는 반드시 리턴(return)문을 사용해서 리턴값을 지정한다.
만약 return문이 없다면 컴파일 오류가 발생한다.
return문이 실행되면 메소드는 즉시 종료된다.
리턴값이 있는 메소드(void)
void로 선언된 리턴값이 없는 메소드에서도 return문을 사용할 수 있다.
다음과 같이 return문을 사용하면 메소드 실행을 강제 종료한다.
return;
메소드 호출
메소드는 클래스 내외부의 호출에 의해 실행된다.
클래스 내부의 다른 메소드에서 호출할 경우에는 단순한 메소드 이름으로 호출하면 되지만, 클래스 외부에서 호출할 경우에는 우선 클래스로부터 객체를 생성한 뒤, 참조 변수를 이용해서 메소드를 호출해야 한다.
그 이유는 객체가 존재해야 메소드도 존재하기 때문이다.
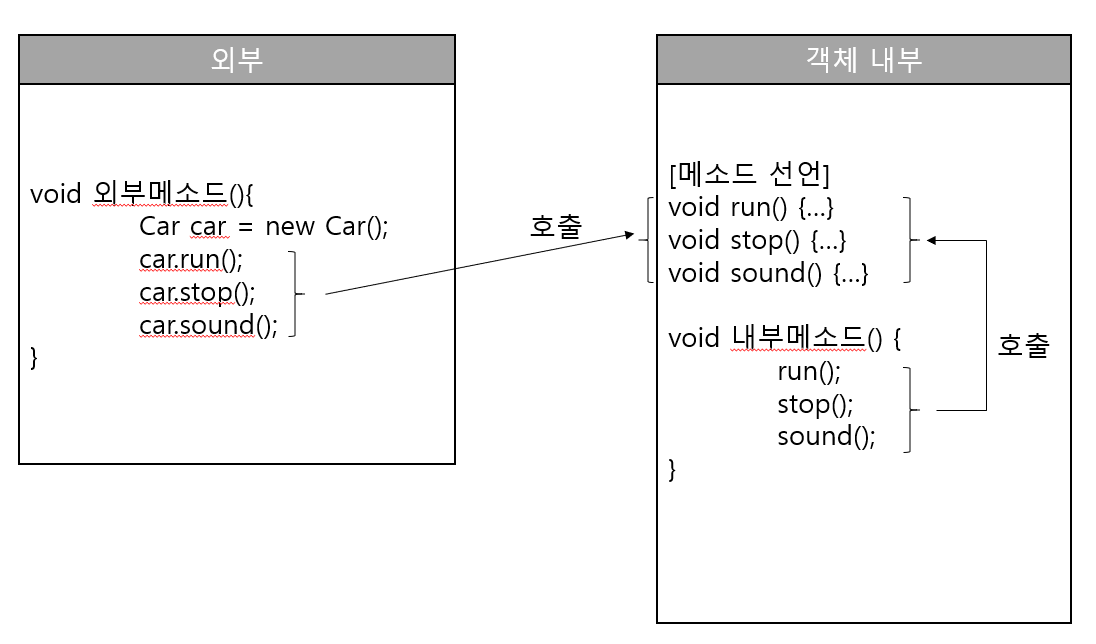
객체 내부에서 호출
클래스 내부에서 다른 메소드를 호출할 경우에는 다음과 같은 형태로 작성하면 된다.
메소드가 매개 변수를 가지고 있을 때에는 매개 변수의 타입과 수에 맞게 매개값을 저장한다.
메소드( 매개값, ... );
예를 들어 method2() 메소드에서 method1() 메소드를 호출하려면 다음과 같이 작성한다.
public class ClassName(){
void method1(String p1, int p2){
}
void method2(){
method1("홍길동", 100);
}
}
메소드가 리턴값이 없거나, 있어도 받고 싶지 않을 경우 위와 같이 모두 호출이 가능하다.
리턴값이 있는 메소드를 호출하고 리턴값을 받고 싶다면 다음과 같이 변수를 선언하고 대입한다.
타입 변수 = 메소드(매개값, ...);
주의해야 할 점은 변수 타입은 메소드 리턴 타입과 동일하거나, 타입 변환이 될 수 있어야 한다.
예를 들어 int 타입은 double 타입으로 자동 변환되기 때문에 int 리턴값은 double 변수에 대입할 수 있다.
public class ClassName(){
int method1(int x, int y){
int result = x+y;
return result;
}
void method2(){
int result1 = method1(10, 20); // result1에는 30이 저장
double result2 = method1(10,20); // result2에는 30.0이 저장
}
}
객체 외부에서 호출
외부 클래스에서 메소드를 호출하려면 우선 다음과 같이 클래스로부터 객체를 생성해야 한다.
메소드는 객체에 소속된 멤버이므로 객체가 존재하지 않으면 메소드도 존재하지 않기 때문이다.
클래스 참조변수 = new 클래스(매개값, ...);
객체가 생성되었다면 참조 변수와 함께 도트(.) 연산자를 사용해서 메소드를 호출할 수 있다.
도트(.) 연산자는 객체 접근 연산자로 객체가 가지고 있는 필드나, 메소드에 접근할 때 사용된다.
참조변수.메소드(매개값, ...); // 리턴값이 없거나, 있어도 리턴값을 받지 않을 경우
타입 변수 = 참조변수.메소드(매개값, ...); // 리턴값이 있고, 리턴값을 받고 싶을 경우
메소드 오버로딩
클래스 내에 같은 이름의 메소드를 여러 개 선언하는 것을 메소드 오버로딩(overloading) 이라고 한다.
하나의 메소드 이름으로 여러 기능을 담는다 하여 붙여진 이름이라 생각할 수 있다.
메소드 오버로딩의 조건은 매개 변수의 타입, 개수, 순서 중 하나가 달라야 한다.
class 클래스{
리턴 타입 메소드 이름 (타입 변수, ...) {...}
무관 동일 매개 변수의 타입, 개수, 순서가 달라야함
리턴 타입 메소드 이름 (타입 변수, ...) {...}
}
메소드 오버로딩이 필요한 이유는 매개값을 다양하게 받아 처리할 수 있도록 하기 위해서이다.
예를 들어 다음과 같이 plus() 메소드가 있다고 가정해보자.
int plus(int x, int y){
int result = x + y;
return result;
}
plus() 메소드를 호출하기 위해서는 두 개의 int 매개값이 필요하다.
하지만 int 타입이 아니라 double 타입의 값을 덧셈하기 위해서는 plus() 메소드를 호출할 수 없다.
해결 방법은 매개 변수가 double 타입으로 선언된 plus() 메소드를 하나 더 선언하는 것이다.
double plus(double x, double y){
double result = x + y;
return result;
}
오버로딩된 메소드를 호출할 경우 JVM은 매개값의 타입을 보고 메소드를 선택한다.
하지만 다음 코드는 어떻게 될까?
int x = 10;
double y = 20.3;
plus(x,y);
첫 번째 매개 변수가 int 타입이고 두 번째 매개 변수가 double 타입인 plus() 메소드가 없기 때문에 컴파일 오류가 날 것 같지만,
사실은 plus(double x, double y) 메소드가 실행된다.
JVM은 일차적으로 매개 변수 타입을 보지만, 매개 변수의 타입이 일치하지 않을 경우, 자동 타입 변환이 가능한지를 검사한다.
첫 번째 매개 변수인 int 타입은 double 타입으로 변환이 가능하므로 최종적으로 plus(double x, double y) 메소드가 선택된다.
메소드를 오버로딩할 때 주의할 점은 매개 변수의 타입과 개수, 순서가 똑같을 경우 매개 변수 이름만 바꾸는 것은 메소드 오버로딩이라고 볼 수 없다.
또한 리턴 타입만 다르고 매개 변수가 동일하다면 이것은 오버로딩이 아니다.
만약 아래와 같이 선언했다면 오버로딩이 아니므로 컴파일 오류가 발생한다.
int divide(int x, inty) {...}
double divide(int boonja, int boonmo) {...}
메소드 오버로딩의 가장 대표적인 예는 System.out.println() 메소드이다.
println() 메소드는 호출할 때 주어진 매개값의 타입에 따라서 오버로딩된 println() 메소드를 호출한다.
객체 지향 프로그래밍의 클래스 구성 멤버를 정리해보았다.
필드, 생성자, 메소드에 대해 정리를 했는데, 내용을 꼼꼼히 보려니 시간이 많이 소요되는 듯 하다.
그래도 꼼꼼히 정리해야 하는 부분이므로 차근차근 진행중이다.
화이팅~
Leave a comment